From Surf Wiki (app.surf) — the open knowledge base
Google matrix
Stochastic matrix representing links between entities

Stochastic matrix representing links between entities
|article-number=275101
A Google matrix is a particular stochastic matrix that is used by Google's PageRank algorithm. The matrix represents a graph with edges representing links between pages. The PageRank of each page can then be generated iteratively from the Google matrix using the power method. However, in order for the power method to converge, the matrix must be stochastic, irreducible and aperiodic.
Adjacency matrix ''A'' and Markov matrix ''S''
In order to generate the Google matrix G, we must first generate an adjacency matrix A which represents the relations between pages or nodes.
Assuming there are N pages, we can fill out A by doing the following:
- A matrix element A_{i, j} is filled with 1 if node j has a link to node i, and 0 otherwise; this is the adjacency matrix of links.
- A related matrix S corresponding to the transitions in a Markov chain of given network is constructed from A by dividing the elements of column "j" by a number of k_j=\Sigma_{i=1}^N A_{i,j} where k_j is the total number of outgoing links from node j to all other nodes. The columns having zero matrix elements, corresponding to dangling nodes, are replaced by a constant value 1/N. Such a procedure adds a link from every sink, dangling state a to every other node.
- Now by the construction the sum of all elements in any column of matrix S is equal to unity. In this way the matrix S is mathematically well defined and it belongs to the class of Markov chains and the class of Perron-Frobenius operators. That makes S suitable for the PageRank algorithm.
Construction of Google matrix ''G''

Then the final Google matrix G can be expressed via S as:
: G_{ij} = \alpha S_{ij} + (1-\alpha) \frac{1}{N} ;;;;;;;;;;; (1)
By the construction the sum of all non-negative elements inside each matrix column is equal to unity. The numerical coefficient \alpha is known as a damping factor.
Usually S is a sparse matrix and for modern directed networks it has only about ten nonzero elements in a line or column, thus only about 10N multiplications are needed to multiply a vector by matrix G.{{cite book
Examples of Google matrix
An example of the matrix S construction via Eq.(1) within a simple network is given in the article CheiRank.
For the actual matrix, Google uses a damping factor \alpha around 0.85.{{cite web
Spectrum and eigenstates of ''G'' matrix

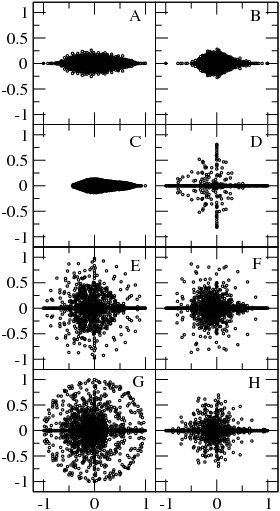
\alpha=1 , blue points show eigenvalues of isolated subspaces, red points show eigenvalues of core component (from {{Cite journal
For 0 there is only one maximal eigenvalue \lambda =1 with the corresponding right eigenvector which has non-negative elements P_i which can be viewed as stationary probability distribution. These probabilities ordered by their decreasing values give the PageRank vector P_i with the PageRank K_i used by Google search to rank webpages. Usually one has for the World Wide Web that P \propto 1/K^{\beta} with \beta \approx 0.9 . The number of nodes with a given PageRank value scales as N_P \propto 1/P^\nu with the exponent \nu = 1+1/\beta \approx 2.1 .{{cite journal |doi-access=free
|article-number=056109
At \alpha=1 the matrix G has generally many degenerate eigenvalues \lambda =1 (see e.g. [6]). Examples of the eigenvalue spectrum of the Google matrix of various directed networks is shown in Fig.3 from and Fig.4 from.
The Google matrix can be also constructed for the Ulam networks generated by the Ulam method [8] for dynamical maps. The spectral properties of such matrices are discussed in [9,10,11,12,13,15]. In a number of cases the spectrum is described by the fractal Weyl law [10,12].
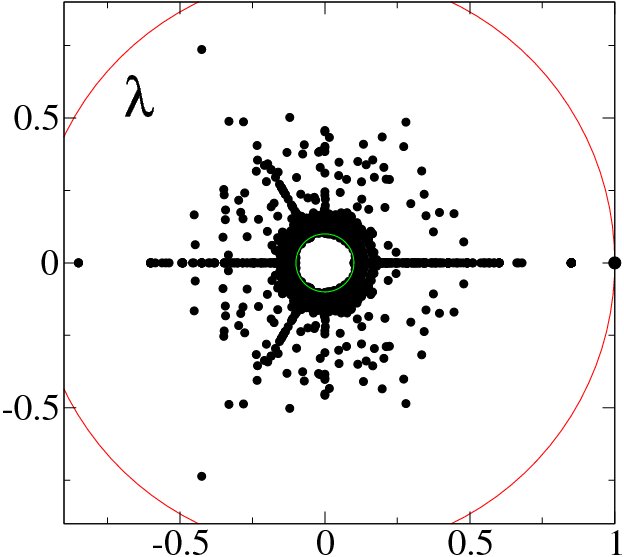

The Google matrix can be constructed also for other directed networks, e.g. for the procedure call network of the Linux Kernel software introduced in [15]. In this case the spectrum of \lambda is described by the fractal Weyl law with the fractal dimension d \approx 1.3 (see Fig.5 from ). Numerical analysis shows that the eigenstates of matrix G are localized (see Fig.6 from ). Arnoldi iteration method allows to compute many eigenvalues and eigenvectors for matrices of rather large size [13].
Other examples of G matrix include the Google matrix of brain [17] and business process management [18], see also. Applications of Google matrix analysis to DNA sequences is described in [20]. Such a Google matrix approach allows also to analyze entanglement of cultures via ranking of multilingual Wikipedia articles abouts persons [21]
Historical notes
The Google matrix with damping factor was described by Sergey Brin and Larry Page in 1998 [22], see also articles on PageRank history [23],[24].
References
- {{Cite journal |hdl-access=free
- {{Cite book
- {{Cite journal
- {{Cite journal
- {{Cite journal
- {{Cite journal
- {{Cite journal
- {{Cite arXiv
- {{Cite journal
- {{Cite journal
- {{Cite journal
- {{Cite journal
- {{Cite journal
- {{Cite arXiv
- {{Cite web
This article was imported from Wikipedia and is available under the Creative Commons Attribution-ShareAlike 4.0 License. Content has been adapted to SurfDoc format. Original contributors can be found on the article history page.
Ask Mako anything about Google matrix — get instant answers, deeper analysis, and related topics.
Research with MakoFree with your Surf account
Create a free account to save articles, ask Mako questions, and organize your research.
Sign up freeThis content may have been generated or modified by AI. CloudSurf Software LLC is not responsible for the accuracy, completeness, or reliability of AI-generated content. Always verify important information from primary sources.
Report